Creating highly reliable control, power,
management and
communications systems in hostile remote environments.
Reliability does not happen by accident.
Reliability comes from the combination of a consistent engineering
methodology with a deep and dynamic understanding of how things fail. When
we compare theory with the real-world, we discover that solutions which work
perfectly in computer models don't always reflect what happens in the
field. These are always failures of imagination.
In the telecommunications field, the term "Carrier Class" has meant
99.999% (frequently called "five nines") uptime and that has been the
traditional reliability goal for land line voice telephone service. We
have always taken for granted that even when the electricity was out, we had
dialtone on our home phones! It is unfortunate that very few of our
current electronic devices (especially our computers and cellphones) could
qualify as "Carrier Class." There has been a great deal of
published works and technical standards created over time related to Carrier
Class telecom services. There are also a great many Carrier Class commercial
products intended for the telecom industry that are perfectly suitable for
applications in other fields. Communications devices, environmental
control system components, remote monitoring and management systems,
high-reliability backup power systems and more. Telecom engineers can be valuable resources outside of telecom!
Here is a list of many common "best practices" that lead to high
reliability.
Be Safe! Use materials and components the way they were intended by their
manufacturer. Being "creative" can be fun and can save
money now but be aware that limitations that are not obvious to the average
person could be lurking just out of sight. Issues of temperature
limitations, shear strengths, spacing, proper torque, corrosion, heat
dissipation, grounding, etc. could be waiting in the shadows. When you
are outside of your training and experience, seek out appropriate
professional advice.
Don't reinvent the wheel. Many tried-and-true solutions exist
out there, ready for you to discover them. Often times the real
challenge is just knowing where to look. Don't be afraid to ask
engineers or SME's (Subject Matter Experts) in other, seemingly unrelated
fields, about possible solutions to your challenges.
Reliability through resiliency. Make sure that the components
you use are not at the limits of their capacity in your application.
The highest quality manufacturers of electronic devices use components at
around half of their rated capacity. The low quality manufacturers
save money by using less-robust components at the limits of their capacity
and gamble on the component manufacturers to have been a bit conservative
with their specifications. When it comes to screws and hardware, it is
important to understand a little material science and to torque down
threaded things to their proper values.
Reliability through redundancy. NASA got us to the Moon and
back by perfecting the concept of the redundant system to a repeatable
science. If your application justifies the expense, secondary,
tertiary and maybe even quaternary backups may be appropriate.
Multiple backup power systems with automated failover capabilities are
common in remote communications facilities supporting emergency
responders. If system downtime means significant revenue impact or
risk to human life, having highly-automated backup systems whenever possible
is appropriate. Some non-life-support applications can benefit from
simple manual backup systems. Another consideration is the
vulnerability of your site to serious damage because of a primary system
failure. For example an enclosed rack-mount computer cabinet cooled by
a single cheap ventilation fan when two or more fans could be installed with
a small amount of extra effort. Or a one million dollar remote
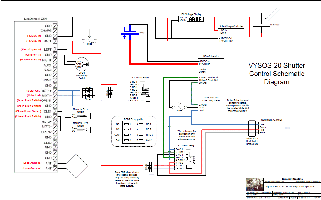
astronomical observatory with a single unreliable fifty dollar dome shutter drive motor.
Reliability through diversity. This applies primarily to
communications, environmental and volumetric fluid controls. For example having one communications
path creates SPoF's (Single Point of Failure ) that can disable a remote
site until a
physical dispatch is made to determine the problem and implement
fixes. That could result in extended downtime. Having a
secondary communications path or second air conditioner (make sure that both
A/C units are fully capable of providing all of the required cooling) or a
secondary flow valve can allow
you to quantify and deterministically bypass a failure point and stay
operational while repairs are planned and implemented.
Effective Out Of Band Management. OOBM is a critical
component of any effective remote management system. A properly
designed OOBM allows you to get into the "back door" of your
remote sites so you can reboot devices, activate semi-automatic backup
systems, monitor sensors, implement failsafe functions and
better-determine the scope and details of a failure. This allows the
skills, tools and spare parts needed for a dispatch to be better-tailored to
the actual problem.
The concept of failsafe. Failsafe means that when things
fail, they are designed to do so into the safest mode possible. For
example emergency fire doors are designed to fail into an unlocked mode
versus a locked mode. SCUBA air regulators are designed to fail-open
instead of fail-closed. It is better when underwater to have excess
airflow than none at all!
Finding and eliminating SPoF's. A SPoF is a Single Point of
Failure. If a single switch, fuse, breaker, valve or outlet can take
your entire remote site down then it is a SPoF. A breaker might be a good
thing in most cases but if it can take your entire site down, maybe it would
be better if different component systems be on different breakers! For
example a shorted-motor should not result in killing your communications
systems. Time spent carefully identifying and eliminating SPoF's
usually pays ten-fold dividends later.
Preventing the cascade failure -or- Big Bad Things made out of nothing.
Many of the greatest disasters in history were the result of cascade
failures. A combination of a series of small and seemingly innocuous
failures (usually not SPoF's) that when combined, result in catastrophe.
For example it could be a combination of a little too much speed + rather limited
visibility + overly-brittle steel plates + rather cold water + poor crew
training + flood doors that swing in the wrong direction + open-topped flood
control chambers + insufficient number of lifeboats + an innocent iceberg. Or it could be a combination
of a failed, cheap cooling fan + no backup router + no OOBM. Or it
could be a failure of a cheap thermostat in an A/C unit + no backup cooling
+ hot-running equipment + small space. Using a creative thinking team
in brainstorming sessions when looking for potential cascade failure
scenarios is often a good approach. No one human being is capable of
effectively critiquing their own engineering designs!
Have a disaster recovery plan. Not every kind of failure can
be prevented. Floods, tornados, earthquakes, fires, volcanoes,
hurricanes, tsunamis, terrorism, wars, vandalism and broken water pipes happen. Decide
what could happen to your remote sites and how much rapid recovery
investment is justifiable.
Know when to delegate and let go. Quite often the best way to
utilize an engineer or other SME is to present them with a problem, a set of
requirements and a budget and ask them to come up with three solutions and a
list of the pros and cons of each. Ask your questions until you feel
that you understand the three proposed solutions and then pick one and then
stay out of the technical details of the implementation. Attempting to
engineer the engineer's engineering just about always results in a
compromised and non-optimal solution that no one will take ownership
of. And if nobody owns it, it WILL fail.
Project Management is a tool, not a solution. And like any
other tool, it can be used to great advantage or it can be misused.
Effective PM can be critical for large, complex projects but it can be a
liability when all you need to do is task someone with filling a gas
tank. Knowing how much PM is appropriate is what separates the great
project managers from the herd. And PM is usually a rather poor tool
for managing ongoing facility-operations.
Operating costs over time. It is inevitable that older
facilities are more expensive to maintain than newer facilities.
Foundations crack. Roofs leak. Metals fatigue. Equipment
becomes obsolete. Moving parts wear out. Make sure to make
long-term operations budget estimates and resource allocation proposals
accordingly.
Accurate documentation. Everybody has time to build stuff but
nobody has time to properly document it. Finding the right degree of implementation
and as-built documentation that should exist for a remote site comes mostly
from experience. But if you are going to make a guess, it is better to
err on the side of too much documentation that not enough. When the
documentation is deficient, technicians make mistakes and downtimes become
much longer. The more deficient the documentation is, the bigger the
resulting mistakes can become. Physical layouts, rack elevations,
logical diagrams, electrical blueprints and electronic schematics all help
the technicians to build things correctly and the operational staff to keep
a remote site running, but only when they are kept accurate and
up-to-date! And effective documentation takes time to create and
verify. In fact it is not unusual that just as much engineering time
can be spent in creating proper implementation and as-built documentation as
technician time is spent in building the facility!
Don't forget the periodic maintenance plans and schedules.
The old saying about an ounce of prevention is true. The importance of
regularly checking fuel
levels and ages, inspections for metal fatigue, signal fade margins,
battery, motor, bearing, filter, etc. should be self evident. Everything that
should be checked on a regular schedule should be documented, tracked and
logged.
Effective task execution. Giving a single technician a list
of tasks and expecting him or her to perform them correctly, effectively and
incrementally in parallel is unrealistic. That isn't an ideal match with
how the human brain performs best. It is generally better to
prioritize the tasks and ask that they be executed one-at-a-time in series,
based on their priority. Also it is generally good practice to empower the
technician to combine minor tasks when it makes common sense. Proposed
major changes to a plan should always be reviewed by the project manager and project engineer. Seeing a 10% or so regular increase in
completeness across all of the project task timelines might look good in
reports but it could conceal sweeping mediocrity in the final product.
Summit Kinetics has over twenty-five years experience building, maintaining and
repairing highly reliable systems in the telecom and
petroleum industries in Alaska. Home to some of the most remote and
hostile environments on earth.
Summit Kinetics
"Building high-reliability systems through resiliency, redundancy and
diversity"
(907)-250-2406
christopher.k.erickson "at" ieee.org